This paper describes the central concepts in Split-C and illustrates how these are used in the process of optimizing parallel programs. We begin with a brief overview of the language as a whole and examine each concept individually in the following sections. The presentation interweaves the example use, the optimization techniques, and the language definition concept by concept.
The remainder of the report is organized into the following sections:
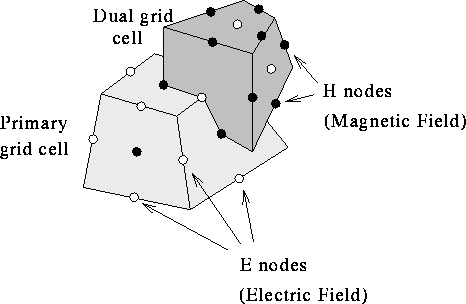
EM3D Grid cells.
To illustrate the novel aspects of Split-C for parallel programs, we use a small, but rather tricky example application, EM3D, that models the propagation of electromagnetic waves through objects in three dimensions. A preprocessing step casts this into a simple computation on an irregular bipartite graph containing nodes representing electric and magnetic field values.
In EM3D, an object is divided into a grid of convex polyhedral cells (typically nonorthogonal hexahedra). From this primary grid, a dual grid is defined by using the barycenters of the primary grid cells as the vertices of the dual grid. The figure shows a single primary grid cell (the lighter cell) and one of its overlapping dual grid cells. The electric field is projected onto each edge in the primary grid; this value is represented as a white dot, an E node, at the center of the edge. Similarly, the magnetic field is projected onto each edge in the dual grid, represented by a black dot, an H node, in the figure.
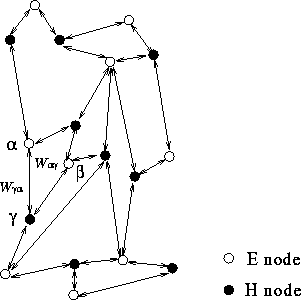
Bipartite graph data structure in EM3D.
The computation consists of a series of "leapfrog" integration steps: on alternate half time steps, changes in the electric field are calculated as a linear function of the neighboring magnetic field values and vice versa. Specifically, the value of each E node is updated by a weighted sum of neighboring H nodes, and then H nodes are similarly updated using the E nodes. Thus, the dependencies between E and H nodes form a bipartite graph. A simple example graph is shown above; a more realistic problem would involve a non-planar graph of roughly a million nodes with degree between ten and thirty. Edge labels (weights) represent the coefficients of the linear functions, for example, W(gamma,alpha) is the weight used for computing alpha's contribution to gamma's value. Because the grids are static, these weights are constant values, which are calculated in a preprocessing step.
A sequential C implementation for the kernel of the algorithm is shown in below. Each E node consists of a structure containing the value at the grid point, a pointer to an array of weights (coeffs), and an array of pointers to neighboring H node values. In addition, the E nodes are linked together by the next field, creating the complete list e_nodes. E nodes are updated by iterating over e_nodes and, for each node, gathering the values of the adjacent H nodes and subtracting off the weighted sum. The H node representation and computation are analogous.
1 typedef struct node_t {
2 double value; /* Field value */
3 int edge_count;
4 double *coeffs; /* Edge weights */
5 double *(*values); /* Dependency list */
6 struct node_t *next;
7 } graph_node;
8
9 void compute_E()
10 {
11 graph_node *n;
12 int i;
13
14 for (n = e_nodes; n != NULL; n = n->next)
15 for (i = 0; i < n->edge_count; i++)
16 n->value = n->value -
17 *(n->values[i]) * (n->coeffs[i]);
18 }
Sequential EM3D, showing the graph node structure and E node
computation.
Before discussing the parallel Split-C implementation of EM3D, consider how one might optimize it for a sequential machine. On a vector processor, one would focus on the gather, vector multiply, and vector sum. On a high-end workstation one can optimize the loop, but since the graph is very large, the real gain would come from minimizing cache misses that occur on accessing n->values[i]. This is done by rearranging the e_nodes list into chunks, where the nodes in a chunk share many H nodes. This idea of rearranging a data structure to improve the access pattern is also central to an efficient parallel implementation.
1 typedef struct node_t {
2 double value;
3 int edge_count;
4 double *coeffs;
5 double *global (*values);
6 struct node_t *next;
7 } graph_node;
8
9 void all_compute_E()
10 {
11 graph_node *n;
12 int i;
13
14 for (n = e_nodes; n != NULL; n = n->next)
15 for (i = 0; i < n->edge_count; i++)
16 n->value = n->value -
17 *(n->values[i]) * (n->coeffs[i]);
18
19 barrier();
20 }
EM3D written using global pointers. Each processor executes this
code on the E nodes it owns. The only differences between this
Split-C kernel and the sequential C kernel are: insertion of the type
qualifier global to the list of value pointers and
addition of the barrier() at the end of the loop.
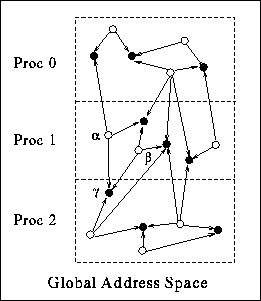
An EM3D graph in the global address space with three processors. With this partitioning, processor 1 owns nodes alpha and beta and processor 2 owns node gamma. The edges are directed for the electric field computation phase.
The first step in parallelizing EM3D is to recognize that the large kernel graph must be spread over the machine. Thus, the structure describing a node is modified so that values refers to an array of global pointers. This is done by adding the type qualifier global in line 5 of the simple global version. The new global graph data structure is illustrated above. In the computational step, each of the processors performs the update for a portion of the e_nodes list. The simplest approach is to have each processor update the nodes that it owns, i.e., owner computes. This algorithmic choice is reflected in the declaration of the data structure by retaining the next field as a standard pointer (see line 6). Each processor has the root of a list of nodes in the global graph that are local to it. All processors enter the electric field computation, update the values of their local E nodes in parallel, and synchronize at the end of the half step before computing the values of the H nodes. The only change to the kernel is the addition of barrier() in line 19 of the program.
Having established a parallel version of the program, how might we optimize its performance on a multiprocessor? Split-C defines a straight-forward cost model: accesses that are remote to the requesting processor are more expensive than accesses that are owned by that processor. Therefore, we want to reorganize the global kernel graph into chunks, so that as few edges as possible cross processor regions (some of the optimizations we use here to demonstrate Split-C features are built into parallel Grid libraries like the Kernighan-Lin and recursive spectral bisection. Thus, for an optimized program there would be a separate initialization step to reorganize the global graph using a cost model of the computational kernel. Load balancing techniques are beyond the scope of this paper, but the global access capabilities of Split-C would be useful in expressing such algorithms.
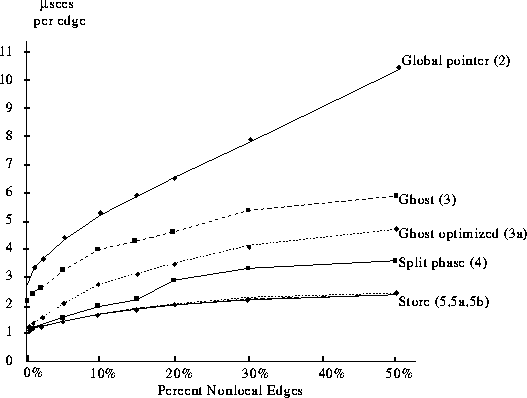
Performance obtained on several versions of EM3D using a synthetic kernel graph with 320,000 nodes of degree 20 on 64 processors. The corresponding program number is in parentheses next to each curve. The y-axis shows the average number of microseconds per edge. Because there are two floating point operations per edge and 64 processors, 1 microsecond per edge corresponds to 128 Mflops.
The figure above gives the performance results for a number of implementations of EM3D on a 64 processor CM-5 without vector units. The x-axis is the percentage of remote edges. The y-axis shows the average time spent processing a single graph edge, i.e., per execution of lines 16-17 in the original global version. Each curve is labeled with the feature and program number used to produce it. The top curve shows the performance of the original version, the first parallel version using global pointers. The other curves reflect optimizations discussed below. For the original version, 2.7 microseconds are required per graph edge when all of the edges are local. As the number of remote edges is increased, performance degrades linearly, as expected.
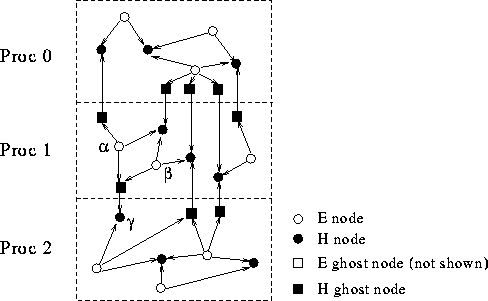
EM3D graph modified to include ghost nodes. Local storage sites are introduced in order to eliminate redundant remote accesses.
The resulting EM3D program is shown below. A new structure is defined for the ghost nodes and a new loop (lines 21-22) is added to read all the remote values into the local ghost nodes. Notice that the node struct has returned to precisely what it was in the sequential version. This means that the update loop (lines 24-27) is the same as the sequential version, accessing only local pointers. The "Ghost" curve in the performance graph shows the performance improvement.
In practice, the performance of parallel programs is often limited by that of its sequential kernels. For example, a factor of two in EM3D can be obtained by carefully coding the inner loop using software pipelining. The performance curve for this optimized version appears in the performance graph as "Ghost optimized." The ability to maintain the investment in carefully sequential engineered software is an important issue often overlooked in parallel languages and novel parallel architectures.
The shape of both "Ghost" curves in the performance graph is very different from our initial version. The execution time per edge increases only slightly beyond the point where 30% of the edges refer to remote nodes. The reason is that as the fraction of remote edges in the synthetic kernel graph increases, the probability that there will be multiple references to a remote node increases as well. Thus, the number of remote nodes referenced remains roughly constant, beyond some threshold. In other words, with an increasing number of remote edges, there are approximately the same number of ghost nodes; more nodes will depend upon these ghost nodes instead of depending upon other local nodes. The graphs obtained from real meshes exhibit a similar phenomenon.
Split-C supports overlapping communication and computation using split-phase assignments. The processor can initiate global memory operations by using a new assignment operator :=, do some computation, and then wait for the outstanding operations to complete using a sync() operation. The initiation is separated from the completion detection and therefore the accesses are called split-phase.
1 typedef struct node_t {
2 double value;
3 int edge_count;
4 double *coeffs;
5 double *(*values);
6 struct node_t *next;
7 } graph_node;
8
9 typedef struct ghost_node_t {
10 double value;
11 double *global actual_node;
12 struct ghost_node_t *next;
13 } ghost_node;
14
15 void all_compute_E()
16 {
17 graph_node *n;
18 ghost_node *g;
19 int i;
20
21 for (g = h_ghost_nodes; g != NULL; g = g->next)
22 g->value = *(g->actual_node);
23
24 for (n = e_nodes; n != NULL; n = n->next)
25 for (i = 0; i < n->edge_count; i++)
26 n->value = n->value -
27 *(n->values[i]) * (n->coeffs[i]);
28
29 barrier();
30 }
EM3D code with ghost nodes. Remote values are read once into
local storage. The main computation loop manipulates only local
pointers.
Reads and writes can be mixed with gets and puts; however, reads and writes do not wait for previous gets and puts to complete. A write operation waits for itself to complete, so if another operation (read, write, put, get, or store) follows, it is guaranteed that the previous write has been performed. The same is true for reads; any read waits for the value to be returned. In other words, only a single outstanding read or write is allowed from a given processor; this ensures that the completion order of reads and writes match their issue order. The ordering of puts is defined only between sync operations.
1 void all_compute_E()
2 {
3 graph_node *n;
4 ghost_node *g;
5 int i;
6
7 for (g = h_ghost_nodes; g != NULL; g = g->next)
8 g->value := *(g->actual_node);
9
10 sync();
11
12 for (n = e_nodes; n != NULL; n = n->next)
13 for (i = 0; i < n->edge_count; i++)
14 n->value = n->value -
15 *(n->values[i]) * (n->coeffs[i]);
16
17 barrier();
18 }
EM3D with pipelined communication
The EM3D kernel using stores is given in the store version below. Each processor maintains a list of "store entry" cells that map local nodes to ghost nodes on other processors. The list of store entry cells acts as an anti-dependence list and are indicated as dashed lines in the graph below. The all_store_sync() operation on line 19 ensures that all the store operations are complete before the ghost node values are used. Note also that the barrier at the end the routine in the split-phase version has been eliminated since the all_store_sync() enforces the synchronization. The curve labeled "Store" in the performance graph demonstrates the performance improvement with this optimization. (There are actually three overlapping curves for reasons discussed below.)
Observe that this version of EM3D is essentially data parallel, or bulk synchronous, execution on an irregular data structure. It alternates between a phase of purely local computation on each node in the graph and a phase of global communication. The only synchronization is detecting that the communication phase is complete.
1 typedef struct ghost_node_t {
2 double value;
3 } ghost_node;
4
5 typedef struct store_entry_t {
6 double *global ghost_value;
7 double *local_value;
8 } store_entry;
9
10 void all_compute_E()
11 {
12 graph_node *n;
13 store_entry *s;
14 int i;
15
16 for (s = h_store_list; s != NULL; s = g->next)
17 s->ghost_value :- *(s->local_value);
18
19 all_store_sync();
20
21 for (n = e_nodes; n != NULL; n = n->next)
22 for (i = 0; i < n->edge_count; i++)
23 n->value = n->value -
24 *(n->values[i]) * (n->coeffs[i]);
25 }
Using the store operation to further optimize the main
routine.
A further optimization comes from the following observation: for each processor, we know not only where (on what other processors) data will be stored, but how many stores are expected from other processors. The all_store_sync() operation guarantees globally that all stores have been completed. This is done by a global sum of the number of bytes issued minus the number received. This incurs communication overhead, and prevents processors from working ahead on their computation until all other processors are ready. A local operation store_sync(x) waits only until x bytes have been stored locally. A new version of EM3D, referred to as "Store 5a," is formed by replacing all_store_sync by store_sync in line 19 of the store code. This improves performance slightly, but the new curve in the performance graph is nearly indistinguishable from the basic store version--it is one of the three curves labeled "Store."
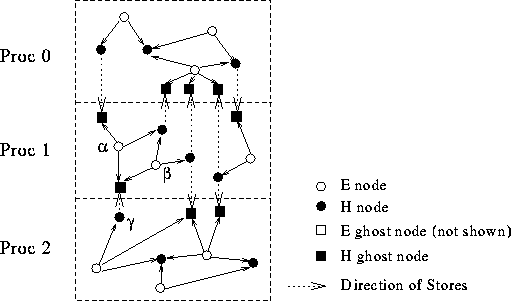
EM3D graph modified to use stores
Again, there is a small performance improvement with the bulk store version of EM3D (called "Store 5b"), but the difference is not visible in the three store curves in the performance graph. The overhead of cache misses incurred when copying the data into the buffer costs nearly as much time as the decrease in message count saves, with the final times being only about 1% faster than those of the previous version.
We have arrived a highly structured version of EM3D through a sequence of optimizations. Depending on the performance goals and desired readability, one could choose to stop at an intermediate stage. Having arrived at this final stage, one might consider how to translate it into traditional message passing style. It is clear how to generate the sends, but generating the receives without introducing deadlock is much trickier, especially if receives must happen in the order data arrives. The advantage of the Split-C model is that the sender, rather than receiver, specifies where data is to be stored, and data need not be copied between message buffers and the program data structures.
Most sequential languages support multidimensional arrays by specifying a canonical linear order, e.g., 1-origin column-major in Fortran and 0-origin row-major in C. The compiler translates multidimensional index expressions into a simple address calculation. In C, for example, accessing A[i][j] is the same a dereferencing the pointer A + i*n + j. Many parallel languages eliminate the canonical layout and instead provide a variety of layout directives. Typically these involve mapping the array index space onto a logical processor grid of one or more dimensions and mapping the processor grid onto a collection of processors. The underlying storage layout and index calculation can become quite complex and may require the use of run-time "shape" tables, rather than simple arithmetic. Split-C retains the concept of a canonical storage layout, but extends the standard layout to spread data across processors in a straight-forward manner.
1 void all_compute_E(int n,
2 double E[n]::,
3 double H[n]::)
4 {
5 int i;
6 for_my_1d(i, n - 1)
7 if (i != 0)
8 E[i] = w1 * H[i - 1] + w2 * H[i] + w3 * H[i + 1];
9 barrier();
10 }
A simple computation on a spread array, declared with a cyclic
layout.To illustrate a typical use of spread arrays, the above program shows a regular 1D analog of our EM3D kernel. The declarations of E and H contain a spreader (::), indicating that the elements are spread across the processors. This corresponds to a cyclic layout of n elements, starting with element 0 on processor 0. Consecutive elements are on consecutive processors at the same address, except that the address is incremented when the processor number wraps back to zero. The loop construct, for_my_1d, is a simple macro that iteratively binds i to the indexes from 0 to n-2 that are owned by the executing processor under the canonical layout, i.e., processor p computes element p, then p + PROCS and so on. Observe, that if n is equal to PROCS this is simply an array with one element per processor.
In optimizing this program, one would observe that with a cyclic layout two remote references are made in line 8, so it would be more efficient to use a blocked layout. Any standard data type can be spread across the processors in a wrapped fashion. In particular, by adding a dimension to the right of the spreader, e.g., E[m]::[b], we assign elements to processors in blocks. If m is chosen equal to PROCS, this corresponds to a blocked layout. If m is greater than PROCS, this is a block-cyclic layout. The loop statement for_my_1d(i,m) would be used to iterate over the local blocks. One may also choose to enlarge the block to include ghost elements at the boundaries and perform the various optimization described for EM3D.
To see how spread arrays can achieve other layouts, consider a generic declaration of the form
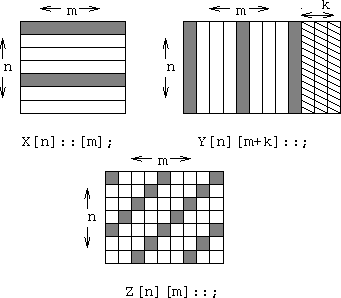
Spread array declarations and layouts, with processor zero's elements highlighted. Assumes n is 7, m is 9, k is 3, and there are 4 processors.
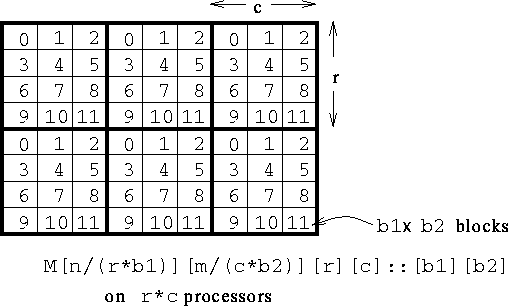
A declaration for a blocked/cyclic layout in both dimensions. Each block shows the number of the processor that owns it. Shown for n=8, m=9, r=4, c=3, where there are 12 processors.
Since the data layout is well-defined, programmers can write their own control macros (like the for_my_1d macro) that iterate over arbitrary dimensions in arbitrary orders. They can also encode subspace iterations, such as iterations over lower triangular, or diagonal elements, or all elements to the left of an owned element. Spread arrays are sometimes declared to have a fixed number of elements per processor, for example, the declaration int A[PROCS] will have a single element for each processor.
The relationship between arrays and pointers in C is carried over to spread arrays in Split-C spread pointers. Spread pointers are declared with the word spread, e.g. int *spread p, and are identical to global pointers, except with respect to pointer arithmetic. Global pointers index the memory dimension and spread pointers index in a wrapped fashion in the processor dimension.

Performance of multiple versions of matrix multiply on 64 Sparc processor CM-5.
The figure above shows the performance of four of matrix multiply versions. The lowest curve, labeled "Unblocked" is for a standard matrix multiply on square matrices up to size 256 by 256. The performance curves for the blocked multiply are shown using n/8 by n/8 blocks: "Unopt" gives the results for a straightforward C local multiply routine with full compiler optimizations, whereas "Blocked" uses an optimized assembly language routine that pays careful attention to the local cache size and the floating point pipeline. A final performance curve uses a clever systolic algorithm, Cannon's algorithm, which involves first skewing the blocks within a square processor grid and then cyclic shifts of the blocks at each step, i.e., neighbor communication on the processor grid. All remote accesses are bulk stores and the communication is completely balanced. It peaks at 413 MFlops which on a per processor basis far exceeds published LINPACK performance numbers for the Sparc. This comparison suggests that the ability to use highly optimized sequential routines on local data within Split-C programs is as important as the ability to implement sophisticated global algorithms with a carefully tuned layout.
Split-C borrows heavily from shared memory models in providing several threads of control within a global address space (similar in some ways to the BBN TC2000 or the Stanford DASH). Virtues of this approach include: allowing familiar languages to be used with modest enhancements (as with Epex, PCP, and ANL), making global data structures explicit, rather than being implicit in the pattern of sends and receives, and allowing for powerful linked data structures. This was illustrated for the EM3D problem above; applications that demonstrate irregularity in both time and space such as the Grobner basis problem and circuit simulation also benefit from these features.
Split-C differs from previous shared memory languages by providing a rich set of memory operations, not simply read and write. It does not rely on novel architectural features, nor does it assume communication has enormous overhead, thereby making bulk operations the only reasonable form of communication as with Zipcode and Fortran-D. These differences arise because of differences in the implementation assumptions. Split-C is targeted toward distributed memory multiprocessors with fast, flexible network hardware, including the Thinking Machines CM-5, Meiko CS-2, Cray T3D and others. Split-C maintains a clear concept of locality, reflecting the fundamental costs on these machines.
Optimizing global operations on regular data structures is encouraged by defining a simple storage layout for global matrices. In some cases, the way to minimize the number of remote accesses is to program the layout to ensure communication balance. For example, an n-point FFT can be performed on p processors with a single remap communication step if p^2 < n, as seen in LogP. In other cases, e.g., blocked matrix multiplication, the particular assignment of blocks to processors less important than load balance and block size.
The approach to global matrices in Split-C stems from the work on data parallel languages, especially HPF and C*. A key design choice was to avoid run-time shapes or dope vectors, because these are inconsistent with C and with the philosophy of least surprises. Split-C does not have the ease of portability of the HPF proposal or of higher level parallel languages. Some HPF layouts are harder to express in Split-C, but some Split-C layouts are very hard to express in HPF. The major point of difference is that in Split-C, the programmer has full control over data layout, and sophisticated compiler support is not needed to obtain performance.
This work was supported in part by the National Science Foundation as a PFF (number CCR-9253705), RIA (number CCR-9210260), Graduate Research Fellowship, and Infrastructure Grant (number CDA-8722788), by Lawrence Livermore National Laboratory, by the Advanced Research Projects Agency of the DOD monitored by ONR under contract DABT63-92-C-0026, by the Semiconductor Research Consortium and by AT&T. The information presented here does not necessarily reflect the position or the policy of the Government and no official endorsement should be inferred.
[2] J. Boyle, R. Butler, T. Disz, B. Glickfeld, E. Lusk, R. Overbeek, J. Patterson, R. Stevens, "Portable Programs for Parallel Processors," Holt, Rinehart, and Winston, 1987.
[3] E. Brooks, "PCP: A Parallel Extension of C that is 99% Fat Free," LLNL Technical Report #UCRL-99673, 1988.
[4] S. Chakrabarti, K. Yelick, "Implementing an Irregular Application on a Distributed Memory Multiprocessor," Proceedings of Principles and Practice of Parallel Programming '93, San Diego, CA.
[5] D. Culler, R. Karp, D. Patterson, A. Sahay, K. Schauser, E. Santos, R. Subramonian, T. von Eicken, "LogP: Towards a Realistic Model of Parallel Computation," Proceedings of Principles and Practice of Parallel Programming '93, San Diego, CA.
[6] F. Darema, D. George, V. Norton, G. Pfister, "A Single-Program-Multiple Data Computational Model for EPEX/FORTRAN," Parallel Computing, Vol. 7, 1988, pp. 11-24.
[7] M. Dubois, C. Scheurich, "Synchronization, Coherence, and Event Ordering in Multiprocessors," IEEE Computer, Vol. 21, No. 2, February 1988, pp. 9-21.
[8] High Performance Fortran Forum, "High Performance Fortran Language Specification Version 1.0", Draft, January 1993.
[9] S. Hiranandani, K. Kennedy, C.-W. Tseng, "Compiler Optimziations for Fortran D on MIMD Distributed-Memory Machines," Proceedings of the 1991 International Conference on Supercomputing.
[10] BBN Advanced Computers Inc., TC2000 Technical Product Summary, 1989.
[11] B. W. Kernighan, S. Lin, "An Efficient Heuristic Procedure for Partitioning Graphs," Bell System Technical Journal, Vol. 49, 1970, pp. 291-307.
[12] D. Lenoski, J. Laundon, K. Gharachorloo, A. Gupta, J. L. Hennessy, "The Directory Based Cache Coherance Protocol for the DASH Multiprocessor," Proceedings of the 17th International Symposium on Computer Architecture, 1990, pp. 148-159.
[13] N. K. Madsen, "Divergence Preserving Discrete Surface Integral Methods for Maxwell's Curl Equations Using Non-Orthogonal Unstructured Grids," RIACS Technical Report #92.04, February 1992.
[14] A. Pothen, H. D. Simon, K.-P. Liou, "Partitioning Sparse Matrices with Eigenvectors of Graphs," Siam Journal Matrix Anal. Appl., Vol. 11, No. 3, July 1990, pp. 430-452.
[15] J. Rose, G. Steele, Jr., "C*: An Extended C Language for Data Parallel Programming," Proceedings of the Second International Conference on Supercomputing, Vol. 2, May 1987, pp. 2-16.
[16] A. Skjellum, "Zipcode: A Portable Communication Layer for High Performance Multicomputing -- Practice and Experience," Draft, March 1991.
[17] T. von Eicken, D. E. Culler, S. C. Goldstein, K. E. Schauser, "Active Messages: a Mechanism for Integrated Communication and Computation," Proceedings of the International Symposium on Computer Architecture, 1992.
[18] C.-P. Wen, K. Yelick, "Parallel Timing Simulation on a Distributed Memory Multiprocessor," Proceedings of the International Conference on CAD, Santa Clara, California, November 1993.